Snowflake snowpro advanced architect practice test
snowpro advanced architect
Question 1
An Architect needs to allow a user to create a database from an inbound share.
To meet this requirement, the users role must have which privileges? (Choose two.)
- A. IMPORT SHARE;
- B. IMPORT PRIVILEGES;
- C. CREATE DATABASE;
- D. CREATE SHARE;
- E. IMPORT DATABASE;
Answer:
bc
Question 2
An Architect on a new project has been asked to design an architecture that meets Snowflake security, compliance, and governance requirements as follows:
1. Use Tri-Secret Secure in Snowflake
2. Share some information stored in a view with another Snowflake customer
3. Hide portions of sensitive information from some columns
4. Use zero-copy cloning to refresh the non-production environment from the production environment
To meet these requirements, which design elements must be implemented? (Choose three.)
- A. Define row access policies.
- B. Use the Business Critical edition of Snowflake.
- C. Create a secure view.
- D. Use the Enterprise edition of Snowflake.
- E. Use Dynamic Data Masking.
- F. Create a materialized view.
Answer:
bef
Question 3
When using the Snowflake Connector for Kafka, what data formats are supported for the messages? (Choose two.)
- A. CSV
- B. XML
- C. Avro
- D. JSON
- E. Parquet
Answer:
cd
Question 4
Which system functions does Snowflake provide to monitor clustering information within a table (Choose two.)
- A. SYSTEM$CLUSTERING_INFORMATION
- B. SYSTEM$CLUSTERING_USAGE
- C. SYSTEM$CLUSTERING_DEPTH
- D. SYSTEM$CLUSTERING_KEYS
- E. SYSTEM$CLUSTERING_PERCENT
Answer:
ac
Question 5
Which of the following are characteristics of how row access policies can be applied to external tables? (Choose three.)
- A. An external table can be created with a row access policy, and the policy can be applied to the VALUE column.
- B. A row access policy can be applied to the VALUE column of an existing external table.
- C. A row access policy cannot be directly added to a virtual column of an external table.
- D. External tables are supported as mapping tables in a row access policy.
- E. While cloning a database, both the row access policy and the external table will be cloned.
- F. A row access policy cannot be applied to a view created on top of an external table.
Answer:
abc
Question 6
A companys daily Snowflake workload consists of a huge number of concurrent queries triggered between 9pm and 11pm. At the individual level, these queries are smaller statements that get completed within a short time period.
What configuration can the companys Architect implement to enhance the performance of this workload? (Choose two.)
- A. Enable a multi-clustered virtual warehouse in maximized mode during the workload duration.
- B. Set the MAX_CONCURRENCY_LEVEL to a higher value than its default value of 8 at the virtual warehouse level.
- C. Increase the size of the virtual warehouse to size X-Large.
- D. Reduce the amount of data that is being processed through this workload.
- E. Set the connection timeout to a higher value than its default.
Answer:
ac
Question 7
Which feature provides the capability to define an alternate cluster key for a table with an existing cluster key?
- A. External table
- B. Materialized view
- C. Search optimization
- D. Result cache
Answer:
b
Question 8
An Architect has been asked to clone schema STAGING as it looked one week ago, Tuesday June 1st at 8:00 AM, to recover some objects.
The STAGING schema has 50 days of retention.
The Architect runs the following statement:
CREATE SCHEMA STAGING_CLONE CLONE STAGING at (timestamp => '2021-06-01 08:00:00');
The Architect receives the following error: Time travel data is not available for schema STAGING. The requested time is either beyond the allowed time travel period or before the object creation time.
The Architect then checks the schema history and sees the following:
CREATED_ON|NAME|DROPPED_ON 2021-06-02 23:00:00 | STAGING | NULL
2021-05-01 10:00:00 | STAGING | 2021-06-02 23:00:00
How can cloning the STAGING schema be achieved?
- A. Undrop the STAGING schema and then rerun the CLONE statement.
- B. Modify the statement: CREATE SCHEMA STAGING_CLONE CLONE STAGING at (timestamp => '2021-05-01 10:00:00');
- C. Rename the STAGING schema and perform an UNDROP to retrieve the previous STAGING schema version, then run the CLONE statement.
- D. Cloning cannot be accomplished because the STAGING schema version was not active during the proposed Time Travel time period.
Answer:
c
Question 9
The table contains five columns and it has millions of records. The cardinality distribution of the columns is shown below: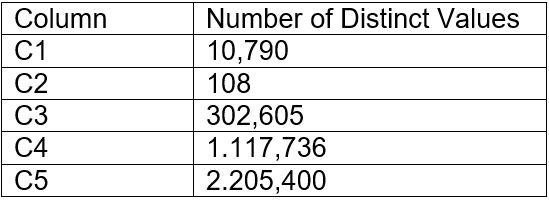
Column C4 and C5 are mostly used by SELECT queries in the GROUP BY and ORDER BY clauses. Whereas columns C1, C2 and C3 are heavily used in filter and join conditions of SELECT queries.
The Architect must design a clustering key for this table to improve the query performance.
Based on Snowflake recommendations, how should the clustering key columns be ordered while defining the multi-column clustering key?
- A. C5, C4, C2
- B. C3, C4, C5
- C. C1, C3, C2
- D. C2, C1, C3
Answer:
d
Question 10
A media company needs a data pipeline that will ingest customer review data into a Snowflake table, and apply some transformations. The company also needs to use Amazon Comprehend to do sentiment analysis and make the de-identified final data set available publicly for advertising companies who use different cloud providers in different regions.
The data pipeline needs to run continuously ang efficiently as new records arrive in the object storage leveraging event notifications. Also, the operational complexity, maintenance of the infrastructure, including platform upgrades and security, and the development effort should be minimal.
Which design will meet these requirements?
- A. Ingest the data using COPY INTO and use streams and tasks to orchestrate transformations. Export the data into Amazon S3 to do model inference with Amazon Comprehend and ingest the data back into a Snowflake table. Then create a listing in the Snowflake Marketplace to make the data available to other companies.
- B. Ingest the data using Snowpipe and use streams and tasks to orchestrate transformations. Create an external function to do model inference with Amazon Comprehend and write the final records to a Snowflake table. Then create a listing in the Snowflake Marketplace to make the data available to other companies.
- C. Ingest the data into Snowflake using Amazon EMR and PySpark using the Snowflake Spark connector. Apply transformations using another Spark job. Develop a python program to do model inference by leveraging the Amazon Comprehend text analysis API. Then write the results to a Snowflake table and create a listing in the Snowflake Marketplace to make the data available to other companies.
- D. Ingest the data using Snowpipe and use streams and tasks to orchestrate transformations. Export the data into Amazon S3 to do model inference with Amazon Comprehend and ingest the data back into a Snowflake table. Then create a listing in the Snowflake Marketplace to make the data available to other companies.
Answer:
b