Why option D is suggested as answer it clearly says readonly access required option D mentioned Alter access
A company wants to collect and process events data from different departments in near-real time. Before storing the data in
Amazon S3, the company needs to clean the data by standardizing the format of the address and timestamp columns. The
data varies in size based on the overall load at each particular point in time. A single data record can be 100 KB-10 MB.
How should a data analytics specialist design the solution for data ingestion?
B
A retail company is using an Amazon S3 bucket to host an ecommerce data lake. The company is using AWS Lake
Formation to manage the data lake.
A data analytics specialist must provide access to a new business analyst team. The team will use Amazon Athena from the
AWS Management Console to query data from existing web_sales and customer tables in the ecommerce database. The
team needs read-only access and the ability to uniquely identify customers by using first and last names. However, the team
must not be able to see any other personally identifiable data. The table structure is as follows: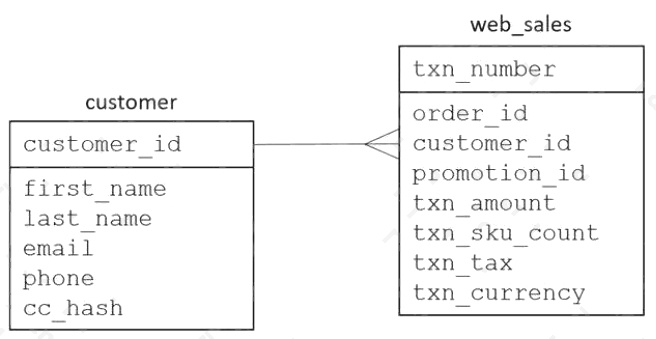
Which combination of steps should the data analytics specialist take to provide the required permission by using the principle
of least privilege? (Choose three.)
B D F
Why option D is suggested as answer it clearly says readonly access required option D mentioned Alter access
A media analytics company consumes a stream of social media posts. The posts are sent to an Amazon Kinesis data stream
partitioned on user_id. An AWS Lambda function retrieves the records and validates the content before loading the posts
into an Amazon OpenSearch Service (Amazon Elasticsearch Service) cluster. The validation process needs to receive the
posts for a given user in the order they were received by the Kinesis data stream.
During peak hours, the social media posts take more than an hour to appear in the Amazon OpenSearch Service (Amazon
ES) cluster. A data analytics specialist must implement a solution that reduces this latency with the least possible operational
overhead.
Which solution meets these requirements?
C
Explanation:
For real-time processing of streaming data, Amazon Kinesis partitions data in multiple shards that can then be consumed by
multiple Amazon EC2
Reference: https://d1.awsstatic.com/whitepapers/AWS_Cloud_Best_Practices.pdf
A company provides an incentive to users who are physically active. The company wants to determine how active the users
are by using an application on their mobile devices to track the number of steps they take each day. The company needs to
ingest and perform near-real-time analytics on live data. The processed data must be stored and must remain available for 1
year for analytics purposes.
Which solution will meet these requirements with the LEAST operational overhead?
C
A retail company stores order invoices in an Amazon OpenSearch Service (Amazon Elasticsearch Service) cluster Indices
on the cluster are created monthly. Once a new month begins, no new writes are made to any of the indices from the
previous months. The company has been expanding the storage on the Amazon OpenSearch Service (Amazon
Elasticsearch Service) cluster to avoid running out of space, but the company wants to reduce costs. Most searches on the
cluster are on the most recent 3 months of data, while the audit team requires infrequent access to older data to generate
periodic reports. The most recent 3 months of data must be quickly available for queries, but the audit team can tolerate
slower queries if the solution saves on cluster costs
Which of the following is the MOST operationally efficient solution to meet these requirements?
D
Explanation:
Reference: https://docs.aws.amazon.com/da_pv/opensearch-service/latest/developerguide/opensearch-service-dg.pdf
A large ride-sharing company has thousands of drivers globally serving millions of unique customers every day. The
company has decided to migrate an existing data mart to Amazon Redshift. The existing schema includes the following
tables.
A trips fact table for information on completed rides.
A drivers dimension table for driver profiles.
A customers fact table holding customer profile information.
The company analyzes trip details by date and destination to examine profitability by region. The drivers data rarely
changes. The customers data frequently changes.
What table design provides optimal query performance?
A
The customers data frequently changes so DISTSTYLE ALL is not correct option as suggested i option A correct answer should be C
A technology company is creating a dashboard that will visualize and analyze time-sensitive data. The data will come in
through Amazon Kinesis Data Firehose with the butter interval set to 60 seconds. The dashboard must support near-real-
time data.
Which visualization solution will meet these requirements?
A
A data analytics specialist is setting up workload management in manual mode for an Amazon Redshift environment. The
data analytics specialist is defining query monitoring rules to manage system performance and user experience of an
Amazon Redshift cluster.
Which elements must each query monitoring rule include?
C
Explanation:
Reference: https://docs.aws.amazon.com/redshift/latest/dg/cm-c-wlm-query-monitoring-rules.html
An online retail company uses Amazon Redshift to store historical sales transactions. The company is required to encrypt
data at rest in the clusters to comply with the Payment Card Industry Data Security Standard (PCI DSS). A corporate
governance policy mandates management of encryption keys using an on-premises hardware security module (HSM).
Which solution meets these requirements?
B
A company leverages Amazon Athena for ad-hoc queries against data stored in Amazon S3. The company wants to
implement additional controls to separate query execution and query history among users, teams, or applications running in
the same AWS account to comply with internal security policies.
Which solution meets these requirements?
C
Explanation:
Reference: https://aws.amazon.com/athena/faqs/
A central government organization is collecting events from various internal applications using Amazon Managed Streaming
for Apache Kafka (Amazon MSK). The organization has configured a separate Kafka topic for each application to separate
the data. For security reasons, the Kafka cluster has been configured to only allow TLS encrypted data and it encrypts the
data at rest.
A recent application update showed that one of the applications was configured incorrectly, resulting in writing data to a
Kafka topic that belongs to another application. This resulted in multiple errors in the analytics pipeline as data from different
applications appeared on the same topic. After this incident, the organization wants to prevent applications from writing to a
topic different than the one they should write to.
Which solution meets these requirements with the least amount of effort?
B
A data analytics specialist is building an automated ETL ingestion pipeline using AWS Glue to ingest compressed files that
have been uploaded to an Amazon S3 bucket. The ingestion pipeline should support incremental data processing.
Which AWS Glue feature should the data analytics specialist use to meet this requirement?
B
Explanation:
Reference: https://docs.aws.amazon.com/prescriptive-guidance/latest/patterns/build-an-etl-service-pipeline-to-load-data-
incrementally-from-amazon-s3-to-amazon-redshift-using-aws-glue.html
A transportation company uses IoT sensors attached to trucks to collect vehicle data for its global delivery fleet. The
company currently sends the sensor data in small .csv files to Amazon S3. The files are then loaded into a 10-node Amazon
Redshift cluster with two slices per node and queried using both Amazon Athena and Amazon Redshift. The company wants
to optimize the files to reduce the cost of querying and also improve the speed of data loading into the Amazon Redshift
cluster.
Which solution meets these requirements?
D
A mobile gaming company wants to capture data from its gaming app and make the data available for analysis immediately.
The data record size will be approximately 20 KB. The company is concerned about achieving optimal throughput from each
device. Additionally, the company wants to develop a data stream processing application with dedicated throughput for each
consumer.
Which solution would achieve this goal?
D
A company analyzes its data in an Amazon Redshift data warehouse, which currently has a cluster of three dense storage nodes. Due to a recent business acquisition, the company needs to load an additional 4 TB of user data into Amazon Redshift. The engineering team will combine all the user data and apply complex calculations that require I/O intensive resources. The company needs to adjust the cluster's capacity to support the change in analytical and storage requirements. Which solution meets these requirements?
A company has 10-15 of uncompressed .csv files in Amazon S3. The company is evaluating Amazon Athena as a one-
time query engine. The company wants to transform the data to optimize query runtime and storage costs.
Which option for data format and compression meets these requirements?
B
Explanation:
Reference: https://aws.amazon.com/blogs/big-data/top-10-performance-tuning-tips-for-amazon-athena/
As per the link For Athena, we recommend using either Apache Parquet or Apache ORC, which compress data by default and are splittable.